
Journée d’études
Traitements et standardisation des corpus multimodaux et web 2.0.
Une journée hommage à Thierry Chanier
Date: 25 mai 2018
Lieu: Site Olympe de Gouges, Université Paris Diderot – Paris 7
Coordination: Céline Poudat, Loïc Liégeois, Ciara Wigham.
Etant donné le travail important que Thierry Chanier a accompli pour la communauté, et spécifiquement pour le consortium Corpus écrits, aujourd’hui CORLI (Corpus, Langues, Interactions), nous souhaitons lui rendre un hommage en organisant une journée particulière qui se tiendra à l’université Paris Diderot. Cette journée d’études sera organisée autour des corpus complexes dans les champs de l’Apprentissage des Langues Médiée par les Technologies (ALMT) et de la Communication Médiée par les Réseaux, qu’il a privilégiés dans ses travaux.
La publication d’un numéro de la revue Corpus est envisagée à la suite de la journée, qui aura pour thématique la question du traitement, de la standardisation et de l’exploration des corpus complexes. Les présentations sur les thématiques ALMT et CMC seront privilégiées. Toute personne ayant participé à la journée, présentateur et participant, sera donc invitée à soumettre un article dans ce numéro. Un appel sera envoyé par la suite.
Site web : https://je-corpus-corli.sciencesconf.org/
Programme :
| 9h30-10h | Accueil des participants |
| 10h-10h30 | Introduction |
| 10h30-11h30 | Christophe Reffay: De Simuligne à MULCE : avancées et obstacles pour le partage |
| 11h30-12h30 | Françoise Blin: Vers une approche écologique et éthique de la création et du partage d’un corpus d’interactions pédagogiques multimodales: l’exemple du projet ISMAEL |
| 12h30-13h | Eva Lacroix: Corpus complexes et Apprentissage des Langues Médié par les Technologies (ALMT) – quoi, pourquoi, comment ? |
| 13h-14h30 | Session poster + Déjeuner |
| 14h30-15h30 | Michael Beisswenger: Building corpora of computer-mediated communication: a rewarding task? |
| 15h30-16h | Julien Longhi: Explorer des corpus de tweets: du traitement informatique à l’analyse discursive complexe |
| 16h-16h30 | Pause |
| 16h30-17h | Céline Poudat & Ciara R. Wigham: Retour sur le projet CoMeRe: réalisations, impact et retombées |
| 17h-17h30 | Christophe Parisse: Données ouvertes pour publication (Titre provisoire) |
| 18h | Apéritif |
Parution
Un ouvrage collectif « Investigating Computer-Mediated Communication: Corpus-based approaches to language in the digital world » édité par Darja Fišer et Michael Beißwenger, suite au colloque cmc-corpora16, vient d’être publié.
Une version en libre accès est disponible à ce lien.
Fišer, Darja: Beißwenger, Michael (Eds., 2017). Investigating Computer-Mediated Communication: Corpus-Based Approaches to Language in the Digital World. Ljubljana: Scientific Publishing House of the Faculty of Arts, University of Ljubljana.


CMCCorpora17

Quelques membres du projet CoMeRe étaient présents à la 5ième CMCCorpora conférence à Bozen/Bolzano en Italie, organisé par EuRAC Research.
En savoir plus : https://cmc-corpora2017.eurac.edu/
Les dates pour CMCCorpora18 sont annoncées : 17-18 septembre 2018 à l’Université d’Anvers en Belgique.
Plateforme #Idéo2017 en ligne
La plateforme #Idéo2017 est en ligne: http://ideo2017.ensea.fr/plateforme/ Cette plateforme est le fruit d’un long travail collectif, dont on retrouve les participants sur le site http://ideo2017.ensea.fr
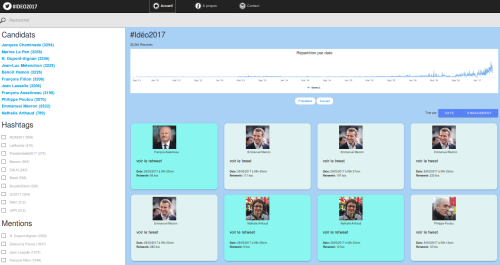
La plateforme capitalise en particulier sur le projet Projet Polititweets lié au Projet CoMeRe (IR corpus), et justifie déjà d’une Production scientifique associée conséquente. Un premier Outil d’analyse de tweets avait été mis en ligne fin 2016 (voir également ce billet), en lien avec les 2 corpus de tweets hébergés sur elle site Ortolang, et la plateforme #Idéo2017 vient concrétiser ce travail, avec une mise à jour du corpus de tweets au fil de la campagne électorale. De nombreuses analyses ont été publiées dans plusieurs journaux et médias, français et étranges, donnant ainsi à voir les avancées et résultats.
Merci aussi aux soutiens: Fondation UCP, UCP, IUT UCP, AGORA et ETIS
Parution

Notre ouvrage collectif, suite au colloque cmc-corpora de Rennes, vient d’être publié dans la collection Humanitiés numériques de l’Harmattan. Plus d’informations ici.
Chapitres :
Wigham, C.R. & Ledegen, G. : Introduction.
Poudat, C., Grabar, N., Paloque-Berges, C., Chanier, T. & Jin, K. : Wikiconflits: un corpus de disussions éditoriales conflictuelles du Wikipédia francophone.
Longhi, J. : Le corpus Polititweets : enjeux institutionnels, juridiques, techniques et philologiques.
Simon, J., Toullec, B. et collègues : Identifier et analyser les discours d’escorte sur Twitter.
Ghliss, Y. & André, F. Après la collecte, l’anonymisation : enjeux éthiques et juridiques dans la constitution du corpus 88milsms.
Vaillant, P. : Annotation de corpus plurilingues : l’expérience du projet CLAPOTY.
Ho Dac, L-M. & Laippala, V. : Le corpus WikiDisc : ressource pour la caractérisation des discussions en ligne.
Fišer, D., Erjavec, T. & Ljubesic, N. : The compilation, processing and analysis of the Janes corpus of Slovene user-generated content.
Jackiewicz, A. : Outiller l’analyse des controverses. Pourquoi s’intéresser aux discours numériques ?
Petersen, J.M. : Multilinguismes et enjeux des pratiques langagières sur un Réseau Social d’Entreprise. Analyse sociolinguistique.
Blanchard, J-F. : Pratiques langagières en langue bretonne sur les réseaux socionumériques : méthode d’une étude de cas.
Mayne, L. : The Affordances and Challenges of WordReference Forums as a Space for Intercultural Exchange.
Chanier, T. : Saisir la parole du citoyen / usager / apprenant en interaction sur les réseaux.
Call for papers: CMC and Social Media Corpora for the Humanities 2017
First Call for Papers: Computer-Mediated Communication and Social Media Corpora for the Humanities 2017
3-4 October 2017
Bolzano/Bozen, Italy
Full details:
https://cmc-corpora2017.eurac.edu/
—————————————————————————————————–
Call for papers
The 5th conference CMC and Social Media Corpora for the Humanities will be held in Bolzano/Bozen, Italy on 3-4 October 2017 and will focus on the collection, analysis and processing of mono and multimodal, synchronous and asynchronous communications. The focus will encompass different CMC genres. These include, but are not limited to, discussion forums, blogs, newsgroups, emails, SMS and WhatsApp, text chats, wiki discussions, social network exchanges (such as Facebook, Twitter, Linkedin), discussions in multimodal and/or 3D environments (virtual worlds, gaming worlds).
The conference will bring together researchers who are interested in the collection, organization, processing, analysis and sharing of CMC data for research purposes. We invite submissions on corpus analysis of various types of CMC data for linguistic or applied linguistic purposes and Natural Language Processing.
The conference is hosted by Eurac Research and will be followed by the 4th Learner Corpus Research Conference, which will be held at the same venue from 5-7 October.
Topics of interest
1. Development of CMC corpora
- Building CMC corpora: from data collection to publication
- Open data for research on CMC: questions of ethics and rights
- Annotation of CMC genres: representation of CMC genres, annotation of linguistic phenomena, metadata
- Multimodal corpora
2. Analysis of CMC corpora
- Sociolinguistic studies of CMC
- Discourse analysis of CMC
- Linguistic characteristics of CMC
- Multimodal aspects of CMC
- Language in contact and code-switching in CMC
- CMC in language learning & teaching
3. Natural Language Processing of CMC
- Normalization
- PoS Tagging
- Lemmatization
- Syntactic parsing
- Named-entity recognition
Submission procedure
We invite submissions for papers, posters and software/corpus demonstrations on any topic relevant to the above list of themes. For this conference, we are requesting extended abstracts (2-4 pages) in English. All abstracts will be peer-reviewed by the scientific committee. All submissions should follow the template which you can download here: MSWord and LaTeX. Please submit your paper via the online conference system.
Paper presentations will consist of a 20 minute talk followed by 10 minutes for questions and discussion.
The poster presentation and software/corpus demonstration session will be opened with each presenter/demonstrator giving a one-minute ‘teaser talk.’
Accepted papers will be published in online proceedings before the conference. After the conference, authors of best-reviewed papers will be invited to submit extended versions of their papers to be published in an edited monograph to appear in 2018.
Important dates
- 1st June: submission deadline
- 25 July: notification of acceptance
- 25 August: submission of camera-ready version
- 3rd & 4th October: conference
Further inquiries
- by email: cmc-corpora2017 @ eurac.edu
Scientific Committee
Chair
- Ciara R. Wigham (LRL, France)
Co-chairs
- Darja Fišer (UL, Slovenia)
- Michael Beißwenger (UDE, Germany)
Members
- Andrea Abel (Eurac Research, Italy)
- Steven Coats (University of Oulu, Finland)
- Daria Dayter (University of Basel, Switzerland)
- Tomaž Erjavec (Jožef Stefan Institute, Slovenia)
- Jennifer Frey (Università di Bologna, Italy)
- Aivars Glaznieks (Eurac Research, Italy)
- Axel Herold (Berlin-Brandenburgische Akademie der Wissenschaften, Germany)
- Dawn Knight (Cardiff University, United Kingdom)
- Julien Longhi (Université de Cergy-Pontoise, France)
- Harald Lüngen (Institut für Deutsche Sprache, Germany)
- Maja Miličević (University of Belgrade, Serbia)
- María-Teresa Ortego-Antón (Universidad Internacional de la Rioja, Spain)
- Muge Satar (Newcastle University, United Kingdom)
- Stefania Spina (University for Foreigners, Italy)
- Egon W. Stemle (Eurac Research, Italy)
- Angelika Storrer (Universitaet Mannheim, Germany)
Organizing Committee
- Egon W. Stemle (Eurac Research, Italy)
- Daniela Gasser (Eurac Research, Italy)
Outil d’exploration corpus de Tweets
Julien Longhi, université de Cergy-Pontoise nous transmet cette information qui permet de faire des analyses sur des corpus de tweets CoMeRe, notamment :
- Longhi, J., Borzic, B., Alkhouli, A.(2016). #Intermittent: constitution d’un corpus lié à un événement discursif controversé. In Chanier T. (ed) Banque de corpus CoMeRe. Ortolang.fr : Nancy. https://hdl.handle.net/11403/comere/cmr-intermittent
- Longhi, J., Marinica, C., Borzic, B. & Alkhouli, A. (2014). Polititweets, corpus de tweets provenant de comptes politiques influents. In Chanier T. (ed) Banque de corpus CoMeRe. Ortolang.fr : Nancy. https://hdl.handle.net/11403/comere/cmr-polititweets
***************
Avant la mise en ligne d’une application #Ideo2017 (http://ideo2017.ensea.fr/, dont le corpus sera ensuite hébergé sur le site du projet), un premier outil est déjà mis à disposition de la communauté pour le traitement de corpus de tweets:
http://ideo2017.ensea.fr/outil-twitter/index.php
Cette interface, développée dans le cadre d’un stage de M2 sciences du langage de Abdelouafi EL OTMANI dirigé par Julien Longhi, permet de faire des recherches dans les corpus Polititweets et #Intermittent, et de générer des sous-corpus spécifiques à ces recherches.
En effet, le format XML-TEI des corpus nécessite une mise en forme pour le traitement dans les outils d’analyse des données textuelles, et nous avons pu constater des difficultés d’interopérabilité entre les pratiques des communautés de constitution de corpus, et d’analyse outillée des discours. Cet outil permettra donc une prise en main plus aisée par les usagers des logiciels mentionnés plus bas.
Cet outil se présente comme un moteur de recherche. Il convient en premier lieu de choisir le corpus souhaité:
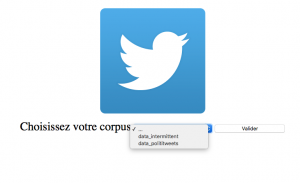
Dans notre cas, nous choisissons Polititweets. L’utilisateur peut ensuite effectuer sa requête, par exemple « démocratie »:
L’utilisateur peut choisir de faire une recherche dans tout le corpus, ou de se focaliser sur un compte twitter spécifique. En cliquant sur « Valider », les résultats apparaissent: contenu des tweets, auteur du tweet, support de production, et nombre de retweets: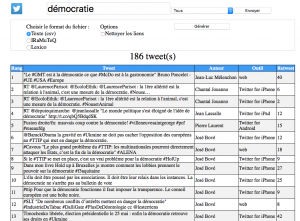
Le menu en haut de la page permet de produire des exports sur mesure pour 2 logiciels d’analyse de données textuelles, Lexico3 et Iramuteq:

En choisissant par exemple Lexico3, sans nettoyer les liens, on obtient un corpus qu’il ne reste plus qu’à copier et utiliser pour une analyse dans le logiciel:

En faisant de même avec Iramuteq, après analyse dans le logiciel, on obtient facilement par exemple l’analyse des similitudes, qui rend notamment compte des cooccurrences de « démocratie »:

Cet outil constitue donc un premier pas vers l’application #Ideo2017: mise à disposition à la communauté, outil intuitif, aide à la constitution de corpus balisés grâce à la médiation de l’outil.
Bonne consultation






AG du consortium CORLI

« Journée-rencontre » du consortium CORLI « CORpus, Langues et Interactions »
Jeudi 12 janvier 2017
Université Paris Diderot- – Bâtiment Olympe de Gouges – Amphi 2
8 place Paul Ricœur (Au bout de la rue Albert Einstein) – 75013
Le comité de pilotage du consortium « CORLI » organise le 12 janvier 2017 une « journée – rencontre » ouverte à tous. Au cours de cette journée seront présentées les avancées et les activités du consortium « CORLI ». La matinée sera consacrée à l’accessibilité des données.
Programme de la journée
9h 00 : Accueil des participants
Matinée – L’accessibilité des ressources
9h 30 – 11h 00 : Diffusion des ressources, interopérabilité et métadonnées
Coordonnateur : Thierry Chanier
Pause
11h 20 – 12h 50 : Méthode d’exploration des corpus : « Des corpus écrits aux corpus
multimodaux »
Coordonnateur : Céline Poudat
DEJEUNER
Après-midi – Consortium « CORLI » : Bilan 2016 et objectifs 2017
14h 00 – 15h 30 : Bilan et objectifs
Coordonnateur : Franck Neveu
Pause
15h 50 – 16h 50 : Débat : Qu’attendez-vous du consortium ?
*****
Inscription nécessaire en suivant le lien : https://form.jotformeu.com/63342008274349
Les personnes participant aux activités du consortium peuvent demander une prise en charge de leur frais de mission.
CoMeRe au colloque CLARIN 2016

Certains membres du projet CoMeRe ont soumis, avec nos collègues européens, un papier au colloque annuel de CLARIN. Michael Beißwenger a presenté le papier intitulé « Integrating corpora of computer-mediated communication into the language resources landscape : Initiatives and best practices from French, German, Italian and Slovenian projects » lors du colloque à Aix en Provence en octobre 2016.
Une vidéo de la présentation se retrouve à ce lien. Le papier est également sur HAL.
Référence bibliographique : Michael Beißwenger, Thierry Chanier, Isabella Chiari, Tomaž Erjavec, Darja Fišer, et al.. (2016). Integrating corpora of computer-mediated communication into the language resources landscape : Initiatives and best practices from French, German, Italian and Slovenian projects. CLARIN Annual Conference 2016, Oct 2016, Aix-en-Provence, France. https://hal.archives-ouvertes.fr/hal-01379621v1.
4ème conférence cmc-corpora en Slovénie

Plusieurs d’entre nous étaient présents à la 4ème conférence que nous co-organisions, après Rennes en 2015, cette année les 27 et 28 septembre en Slovénie.
les diapos des présentations sont à ce lien
Voici le fil Tweeter.
[View the story « 4th Conference on
CMC and Social Media Corpora for the Humanities » on Storify]
En savoir plus : http://cmc-corpora.org
